Terminologies in Hypothesis Testing
In my previous article, we went through the story of the necessity of hypothesis testing, the types of hypothesis and the way we form the hypothesis for testing.

In our quest of exploration, our next stop is understanding the terminologies involved in hypothesis testing. Lets study them together!
- Hypothesis: Now we know that hypothesis are claims that have to be tested. Here, H0 represents a theory that has been put forward, either because it is believed to be true or because it is to be used as a basis for argument, but has not been proved. And H1 is the contradictory statement to H0.

2. Level of Significance (or alpha): The maximum value of type one error which we would be willing to risk in called level of significance. Here, type one error is the probability of rejecting H0 when actually, H0 is true. According to the diagram above, the level of significance is equal to 5% or (100–95)%.
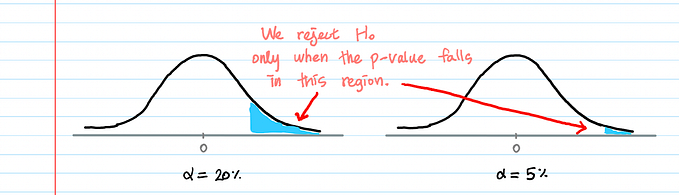
3. Rejection region or Critical Region: It is that region of the plot which is obtained by using the level of significance (or alpha). If the calculated value of the test statistic falls in this region, we reject H0. The total area under the rejection region forms the level of significance. We can get three types of rejection region based on the alternative hypothesis (i) right tailed, (ii) left tailed or (iii) two tailed.

4. Acceptance region: It is the region left over, other than the rejection region. If the calculated test statistic falls in this region, we may accept H0 at alpha% significance.
5. Test Statistic: It is the calculated value by using the sample observations and by assuming that H0 is correct. Therefore, we use the claim made as the null hypothesis, H0, and obtain a test statistic (the calculated value). We would be studying about them in detail in the following article.
Final decision for testing based on the calculated test statistic: The final conclusion for testing of hypothesis is done by dividing the entire sample place into two regions (i) Acceptance region (when the test statistic falls in this region, we accept H0) and (ii) Rejection region or Critical Region (when the test statistic falls in this region, we reject H0).
6. p-value: It gives the probability that the difference between the sample and population parameter is due to chance. Hence if p-value is less, then we can say that this difference between the sample and the population is not much due to chance and hence we can say that they are significantly different. In other words, it is the area of the region to the right of the calculated test statistic.
Final decision based on the p-value: Whenever p-value is less than the decided level of significance at which we are conducting the testing, we reject H0, whereas, if p-value is greater than alpha, we may accept H0 at alpha% level of significance.
Further topic of Discussion
Certainly, there are numerous other factors at play. We would be going over them in the following posts. In order to further understand the basic forms of test statistics with their R codes and interpretations. Stay Tuned for my next post :)