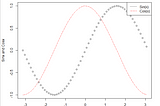
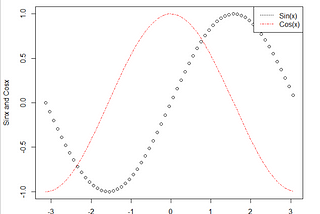
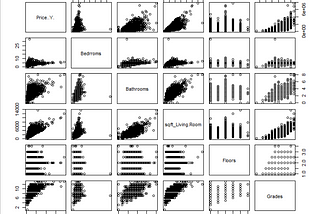
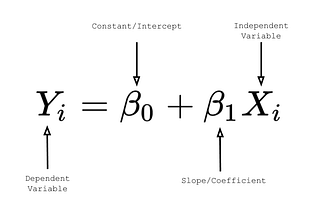Anushka AgrawalDescriptive Statistics with Basic Data Visualization in R programmingR programming language is an extremely versatile and user friendly software for programming. It is commonly used for statistical analysis…May 14, 2021May 14, 2021
Anushka AgrawalData Science MisconceptionsGiven below are a series of statements that I have heard over time! They might make sense initially, but lets analyze it deeper to come to…May 11, 2021May 11, 2021
Anushka AgrawalinNerd For TechStatistical Distributions for a career in Data ScienceLike we discussed, you need to know basics of statistics to be able to analyze the data better. And one topic of statistics, the most…May 10, 2021May 10, 2021
Anushka AgrawalinNerd For TechMust’ve skills for a career in Data Science and their free-resourcesIn my previous article, we went over some of the foundational topics used by Data Science professionals. In order to develop the…May 9, 2021May 9, 2021
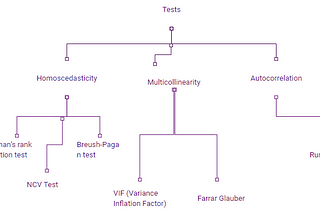
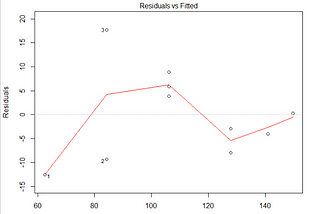
Anushka AgrawalinNerd For TechTest for Heteroscedasticity, Multicollinearity and AutocorrelationIn the articles earlier, we understood the importance of observing the three behaviors in the model: Homoscedasticity, Multicollinearity…May 7, 2021May 7, 2021
Anushka AgrawalinNerd For TechMultiple Linear RegressionIn the last two articles, we explored the concept of Simple Linear Regression Model (i.e., regression involving two variables). Although…May 6, 2021May 6, 2021
Anushka AgrawalLinear Regression Model-Part 2In my previous article, we went over the model fitting for the given data of percentage of hardwood pulp in the paper(X) and the tensile…May 5, 2021May 5, 2021
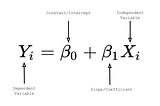
Anushka AgrawalinNerd For TechSimple Linear Regression Modeling-Part 1Regression Analysis is one of the most acknowledged and useful tools of statistics. It is one of the most efficient ways to understand the…May 5, 2021May 5, 2021
Anushka AgrawalTesting for NormalityIn my previous article, we went over the single variable hypothesis testing. Likewise, we can apply the tests for the double variable…May 4, 2021May 4, 2021
Anushka AgrawalTest Statistics for Hypothesis Testing in Statistics with Functions in R ProgrammingIn my previous article, we talked about the terminology in the statistical world of hypothesis testing.May 3, 2021May 3, 2021